Phi-3-vision
前回は、Microsoft Research が開発した SLM(Small Language Model) Phi-3 を .NET(C#) でローカル実行する方法を説明しました。
前回は、テキスト入力をサポートするモデルを使用しましたが、今回は、画像入力をサポートするモデル Phi-3-vision を使用したコード例を説明します。
今回も Hugging Face で公開されている ONNX 形式のモデルを使用したいと思います。2024/06 現在では、以下のモデルが公開されています。
CPU, CUDA 向けのモデルが公開されており、現状では、DirectML 向けのモデルは公開されていません。CUDA 向けのモデルを使用する場合には、もちろん、NVIDIA GPU が必要で、CUDA のセットアップも必要となります。
さらに、CUDA 向けのモデルは、以下の 2 つのモデルが公開されています。
FP16 は、INT4 より精度が高く、INT4 は、FP16 よりパフォーマンスが高いということでしょう。
ONNX ランタイム向けに最適化された ONNX 形式ファイルのダウンロード
前回 と同様に、huggingface-cli でモデルをダウンロードします。
CPU 向け ONNX モデルをダウンロードする場合
huggingface-cli download microsoft/Phi-3-vision-128k-instruct-onnx-cpu --include cpu-int4-rtn-block-32-acc-level-4/* --local-dir .
FP16 CUDA 向け ONNX モデルをダウンロードする場合
huggingface-cli download microsoft/Phi-3-vision-128k-instruct-onnx-cuda --include cuda-fp16/* --local-dir .
INT4 CUDA 向け ONNX モデルをダウンロードする場合
huggingface-cli download microsoft/Phi-3-vision-128k-instruct-onnx-cuda --include cuda-int4-rtn-block-32/* --local-dir .
生成 AI 用 ONNX ランタイムのインストール
Visual Studio 2022 で、コンソールアプリケーションを作成し、以下のパッケージを Nuget からインストールします。
CPU 向け ONNX モデルを使用する場合
CUDA 向け ONNX モデルを使用する場合
ONNX ランタイムは、CPU 向け、CUDA 向け、DirectML 向けで、パッケージが分かれているので、モデルによってパッケージを使い分けます。
モデルの配置
ダウンロードした各ファイルをプロジェクトにコピーします。 コピーしたすべてのファイルのプロパティ [出力ディレクトリにコピー] を [新しい場合はコピーする] に設定します。
これで、ビルド時の出力ディレクトリに各ファイルがコピーされるようになります。
コード サンプル
モデルに入力したい画像を用意しておきます。
以下のようにコードを書きます。
用意した画像のパスを imagePath に設定します。
using Microsoft.ML.OnnxRuntimeGenAI;
using System.Diagnostics;
namespace Phi3VConsoleApp001
{
internal class Program
{
static void Main(string[] args)
{
// システムプロンプト
var systemPrompt = "あなたはAIアシスタントで、ユーザーがアップロードした画像を詳しく説明する能力があります。";
// ユーザープロンプト
var userPrompt = "この画像の内容を教えて下さい。";
// 画像のパス
string imagePath = @"<入力画像のパス>";
// プロンプトのテンプレート
var prompt = $@"<|system|>{systemPrompt}<|end|><|user|><|image_1|>{userPrompt}<|end|><|assistant|>";
// モデルが格納されているパス
string modelDir = Path.Combine(AppDomain.CurrentDomain.BaseDirectory, @"models\cpu-int4-rtn-block-32-acc-level-4");
//string modelDir = Path.Combine(AppDomain.CurrentDomain.BaseDirectory, @"models\cuda-fp16");
//string modelDir = Path.Combine(AppDomain.CurrentDomain.BaseDirectory, @"models\cuda-int4-rtn-block-32");
var sw = Stopwatch.StartNew();
// モデルのロード
using Model model = new(modelDir);
using MultiModalProcessor processor = new(model);
using var tokenizerStream = processor.CreateStream();
sw.Stop();
Console.WriteLine($"Model loading took {sw.ElapsedMilliseconds} ms.");
sw = Stopwatch.StartNew();
Console.WriteLine("Processing image and prompt...");
using var images = Images.Load(imagePath);
var inputTensors = processor.ProcessImages(prompt, images);
Console.WriteLine("Generating response...");
// 各パラメータを設定
using GeneratorParams generatorParams = new GeneratorParams(model);
generatorParams.SetSearchOption("max_length", 3072);
generatorParams.SetInputs(inputTensors);
// 応答の生成
using var generator = new Generator(model, generatorParams);
while (!generator.IsDone())
{
try
{
generator.ComputeLogits();
generator.GenerateNextToken();
// トークンの取り出し
var outputTokens = generator.GetSequence(0)[^1];
// トークンのデコード
var output = tokenizerStream.Decode(outputTokens);
Console.Write(output);
}
catch (Exception ex)
{
Debug.WriteLine(ex);
break;
}
}
Console.WriteLine();
sw.Stop();
Console.WriteLine($"Response generation took {sw.ElapsedMilliseconds} ms.");
}
}
}
実行結果
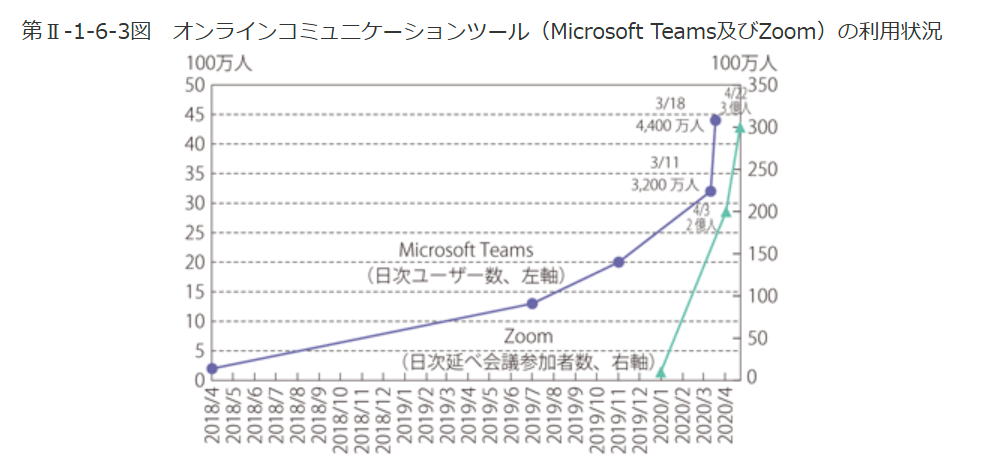
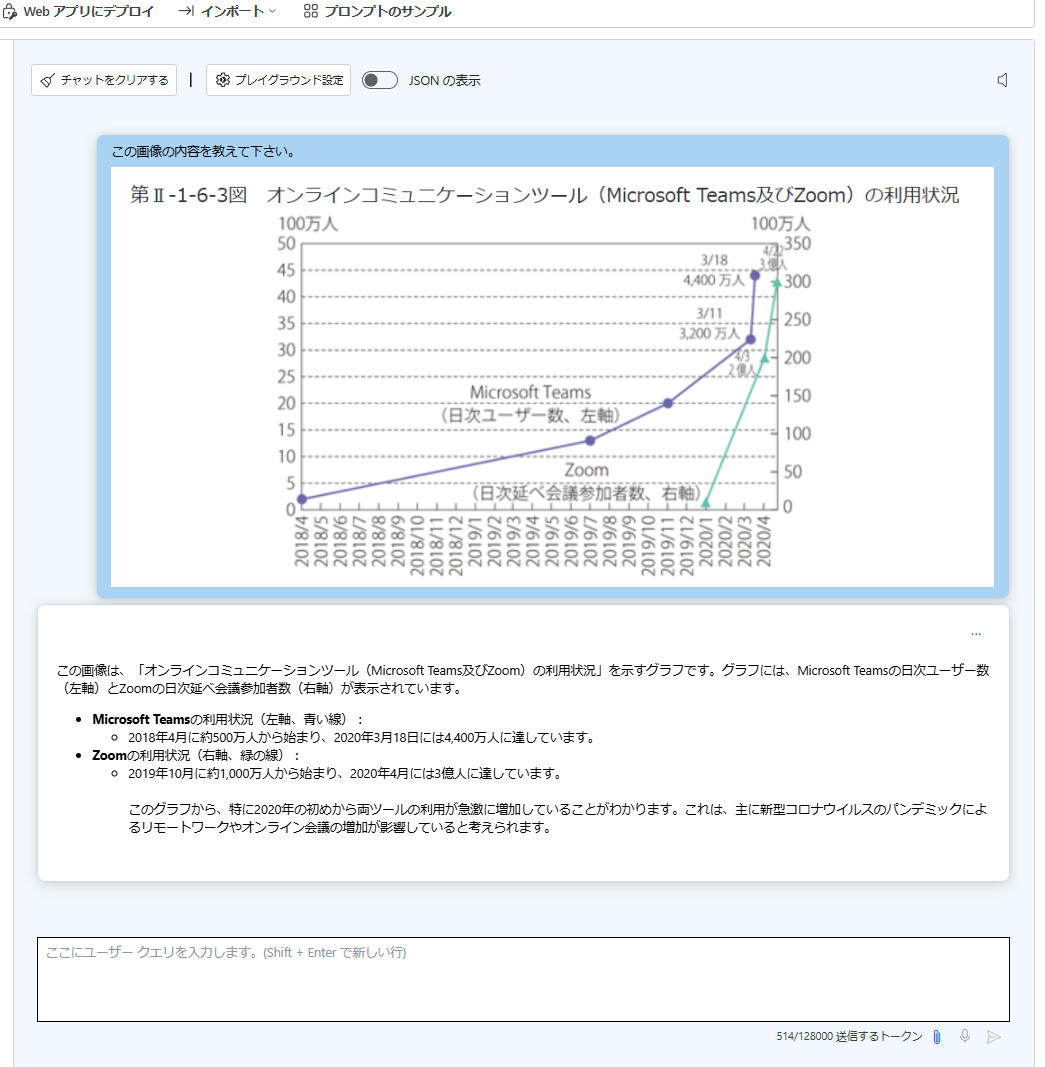
画像は、以下のレポートの「第Ⅱ-1-6-3図 オンラインコミュニケーションツール(Microsoft Teams及びZoom)の利用状況」をキャプチャーして使用しました。
以下は、キャプチャーした画像です。
CPU 向け ONNX モデルでの実行結果は、以下のようになります。回答生成に、158 秒程かかりました。
おおむね内容はあっているようにも見えますが、「データは2018年1月から」と X 軸の開始を読み間違えたり、Zoom のプロットがない 2020/01 以前の期間についても説明がされていたりします。
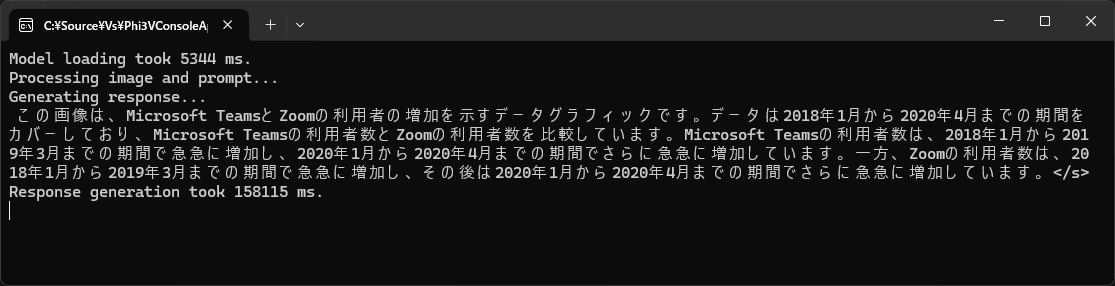
回答生成時は、CPU が、90% 近くまで使用されます。
FP16 CUDA 向け ONNX モデルでの実行結果は、以下のようになります。回答生成に、592 秒程かかりました。
CPU とは異なり、X 軸の開始年月の読み間違えはなくなっています。Zoom のプロットがない 2020/01 以前の期間についての説明は改善されていません。
回答生成時は、GPU が、100% 近くまで使用されます。私が使用している GPU の性能が低いのはあると思いますが、10 分くらいこの状態です。
INT4 CUDA 向け ONNX モデルでの実行結果は、以下のようになります。回答生成に、141 秒程かかりました。
FP16 CUDA 向け ONNX モデルと同様の結果に見えます。CPU 向け ONNX モデルよりわずかに速く処理が終わっています。

こちらも回答生成時は、GPU が、100% 近くまで使用されます。
同じタスクを GPT-4o で行ったところ、Teams と Zoom の系列を正しく読み取ることができており、Zoom の開始時期に誤りはあるもののその他は正しく説明されています。応答は数秒で返ってきます。
Phi-3-vision を利用することで、ローカルで画像を入力としたタスクが実行できます。GPT-4o と比較すると精度が劣るようにも見えますが、今回使用した画像よりも簡易なものであれば、活用ができるシーンもあるのではないでしょうか。これくらいの精度のモデルが、容易にローカル実行できるという視点で見るべきでしょう。 また、スペックはある程度のものが必要となりますが、今後 Copilot+ PC により SoC に NPU が標準搭載されるようになれば、その点は改善されるようになると思います。 当然、Phi-3-vision の後続モデルも開発が継続されていると思われますので、現状を見ると、今後に非常に期待できる性能だと思います。
コメント (0)
コメントの投稿